Как мы недавно писали, в вышедшем обновлении VMware vSphere 6 Update 1 есть полноценное средство обновления компонентов виртуальной инфраструктуры vSphere Update Manager (VUM), доступное для vSphere Web Client. Ранее VUM можно было использовать только из "толстого" (C#) клиента vSphere Client, и это было одной из ключевых причин неиспользования веб-клинта от VMware в крупных инфраструктурах.
Теперь vSphere Update Manager полноценно присутствует как оснастка Web Client:
Кстати, если вы хотите использовать Update Manager в vCenter Server Appliance (vCSA), то вам все равно придется скачать ISO-шник vCenter для Windows, так как VUM находится именно там.
В левом сайдбаре можно выбрать нужный сервер Update Manager и работать с ним. Пройдитесь по настройкам на вкладках:
Далее нужно создать новый базовый уровень (Baseline) по обновлениям. Нажмите зеленый плюсик в разделе Hosts Baselines:
Также базовый уровень можно создать для виртуальных машин (обновления VMware Tools) и виртуальных модулей (Virtual Appliances):
Создадим новый базовый уровень:
Отмечаем правила для обновления виртуальных модулей:
На вкладке Patch Repository вы видите не только список автоматически добавленных патчей для хостов, но и можете добавить патчи вручную через Web Client:
Для разных хостов можно применять разные образы обновлений VMware ESXi (добавляются вручную) и даже делать это одновременно:
В разделе VA Upgrades можно посмотреть доступные версии виртуальных модулей, а удобная функция по клику на ссылку "EULA" в соответствующей колонке позволяет не принимать условия лицензии каждый раз при развертывании. Нажимаем "Go to compliance page":
Попадаем в раздел vCenter, где мы можем привязывать базовые уровни к хостам, сканировать на наличие обновлений, тестировать обновления путем их "отстаивания" на выделенных для целей стейджинга хост-серверах, а также проводить обновление хостов (Remediate):
В контекстном меню Web Client для хостов есть пункт Update Manager, который позволяет вызвать его функции (например, просканировать на наличие обновлений или обновить):
Более подробно об Update Manager для vSphere Web Client можно прочитать вот тут. Материалы статьи взяты тут.
Таги: VMware, vSphere, Update, Update Manager, ESXi, Web Client
После краткого анонса на прошедшей недавно конференции VMworld 2015, компания VMware объявила о выпуске первого пакета обновления для своей флагманской платформы виртуализации - VMware vSphere 6 Update 1 (включая ESXi 6.0 Update 1 и vCenter 6.0 Update 1).
Что нового появилось в Update 1 (полезного, прямо скажем, немного):
Customer Experience Improvement Program (CEIP) - возможность принять участие в программе улучшения продуктов VMware (без передачи данных о клиенте).
Интерфейс Suite UI теперь включен по умолчанию в vSphere Web Client.
Поддержка SSLv3 теперь отключена по умолчанию.
vCSA Authentication for Active Directory - теперь виртуальный модуль с vCenter поддерживает только методы шифрования AES256-CTS/AES128-CTS/RC4-HMAC для аутентификации Kerberos между vCSA и Active Directory.
Поддержка установщика HTML 5 для нового развертывания и апгрейда:
Установка с установщиком HTML 5 для целевого vCenrer Server - поддерживается.
Апгрейд с установщиком HTML 5 для целевого vCenrer Server - не поддерживается.
Апгрейд vCenter Server из командной строки - поддерживается.
Виртуальный модуль vCSA можно развернуть как напрямую на ESXi, так и через сервер vCenter на хосте ESXI.
Возможность конвертации vCSA во внешний Platform Services Controller (PSC).
Интерфейс VMware Appliance Management Interface (VAMI) в виртуальном модуле vCSA теперь вернулся и доступен по ссылке https://[ip-адрес или имя VCSA]:5480.
Возможность накатывания патчей по URL (по умолчанию указан онлайн-репозиторий VMware).
Отдельный HTML 5 интерфейс для PSC, доступный по ссылке:
https://[IP-адрес VCSA]/psc
Это нужно для того, чтобы администратор мог работать с конфигурациями Single Sign-On (SSO) и другими связанными функциями, когда vSphere Web Client по каким-либо причинам недоступен.
Build-2-Build upgrade support - обновлять виртуальный модуль vCSA можно по новой схеме обновлений: не обязательно ставить новый модуль поверх предыдущей версии. Теперь можно смонтировать новый ISO-образ в уже готовую виртуальную машину с vCSA и запустить процедуру обновления.
Скачать VMware vSphere 6 Update 1 можно по этой ссылке.
Наконец-то стал доступен полноценный Update Manager Web Client. Одна из главных причин, по которым пользователи не отказывались от старого vSphere Client для Windows (так как в нем есть полноценный VUM), теперь устранена.
Также в Update Manager появилось следующее:
libxml обновлен до версии 2.9.2.
Опция реинициализации СУБД для VUM теперь доступна Update Manager Utility в категории Database Settings.
Поддержка новых СУБД.
Microsoft SQL 2008 R2-SP3
Microsoft SQL 2012 SP2 (Standalone и Clustered)
Microsoft SQL 2014(Clustered)
Microsoft XML обновлен на MSXML6.dll.
Oracle (Sun) JRE package обновлен на версию 1.7.0_80.
По умолчанию отключена поддержка SSLv3.
Скачивается VMware vSphere Update Manager 6.0 Update 1 вместе с vCenter.
Наверняка некоторые из вас знают, что в новой версии платформы виртуализации VMware vSphere 6 появилась полезная возможность Guest User Mappings. Она позволяет пользователю инфраструктуры SSO (Single-Sign On) предоставить доступ в гостевую ОС виртуальной машины, чтобы постоянно не вводить логин-пароль, а сразу получать доступ к приложениям внутри ВМ. Для этого используется механизм Guest Authentication (vgauth).
Делается это в следующем разделе VMware vSphere Web Client выбранной виртуальной машины:
Manage -> Settings -> Guest User Mappings
Здесь мы нажимаем кнопку "Authenticate" и вводим логин и пароль администратора гостевой ОС:
Далее нажимаем "+" и выбираем пользователя SSO, который будет иметь доступ к консоли виртуальной машины. Его аутентификация будет проходить автоматически:
После этого для данного аккаунта SSO (пользователя vSphere) можно работать с виртуальной машиной и не испытывать неудобств при доступе к ее консоли.
На днях компания Veeam выпустила обновленную версию продукта для комплексного мониторинга и решения проблем в виртуальной среде Veeam Management Pack v8 for System Center.
Новые возможности Veeam Management Pack v8 for System Center:
App-to-metal visibility
Это основная функция решения, которая позволяет организовать отслеживание всех компонентов физической и виртуальной инфраструктуры и связей между ними. Ниже раскрывается сущность этих улучшений, в следующих версиях эти функции будут совершенствоваться.
Полная поддержка VMware vSphere 6 - теперь поддерживаются все новые возможности, такие как Virtual Volumes Datastores (VVOLs), компоненты vCenter, лицензирования и сетевого взаимодействия.
Улучшения Veeam Task Manager for Hyper-V - в новом таск-менеджере поддерживаются виртуальные машины на хранилищах SMB 3.0, а также новые метрики, такие как CPU dispatch time. Кроме того, теперь есть представления кластера Hyper-V и полная совместимость с метриками System Center Virtual Machine Manager и Operations Manager.
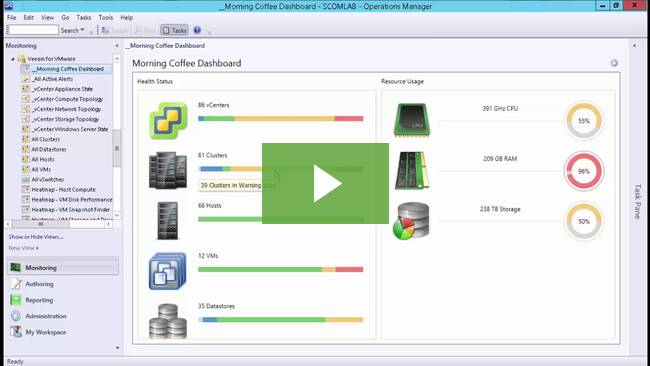
Veeam Morning Coffee Dashboard - новое представление с удобной суммарной информацией по инфраструктуре, на которое первым делом смотрит системный администратор за чашкой утреннего кофе. Отчет Morning Coffee содержит такие показатели, как "VM density" (плотность ВМ на хосте) и уровень нагрузки на вычислительные ресурсы и системы хранения.
Capacity planning and right sizing - теперь функции планирования мощностей виртуальной инфраструктуры значительно расширились и теперь содержат следующие сценарии и представления:
- Host Failure Modeling (моделирование ситуации отказа хоста)
- Performance Forecast for vSphere Datastores (прогноз производительности для хранилищ vSphere)
- Performance Forecast for Hyper-V Storage (прогноз производительности для систем хранения Hyper-V)
- Performance Forecast for vSphere and Hyper-V Clusters (прогноз производительности для кластеров vSphere и Hyper-V)
- Virtual Machine Capacity Prediction (прогноз использования ресурсов виртуальными машинами)
- Resize VMs to reclaim resources (перераспределение ресурсов виртуальных машин)
- Capacity planning for hybrid cloud (планирование ресурсов для гибридного облака)
- Capacity planning for Veeam Backup Repositories (планирование ресурсов для репозиториев Veeam Backup & Replication)
Улучшения планирования для Microsoft Azure или VMware vCloud Air
Отчет для планирования ресурсов был обновлен в соответствии с особенностями Azure и vCloud Air, и теперь с его помощью можно точно прогнозировать количество и тип ресурсов для переноса рабочих нагрузок в облако.
Улучшения отслеживания снапшотов
Забытые снапшоты и контрольные точки могут быстро разрастаться, занимать дисковое пространство и снижать производительность системы. С помощью "тепловых карт" (heat maps) вы сможете узнать, для каких виртуальных машин есть снапшоты и контрольные точки. Также доступен подробный отчет по иерархии снимков состояния, с указанием даты создания и комментариев.
Прочие улучшения:
Улучшенная визуализация топологий виртуальных ресурсов
Улучшенная видимость объектов Veeam Backup and Replication
Больше подробностей о Veeam Management Pack v8 for System Center на русском языке можно узнать на этой странице. Скачать продукт можно по этой ссылке.
Таги: Veeam, MP, Update, Microsoft, Hyper-V, System Center, SC VMM, Monitoring
Уже где-то год прошел с момента релиза версии 6.1 решения для виртуализации сетей виртуального и физического датацентра VMware NSX. Поэтому VMware давно уже было пора обновить продукт и согласовать его с последними версиями линейки продуктов для серверной и десктопной виртуализации. Как мы все давно ждали, на днях вышла обновленная версия VMware NSX 6.2, где появилась масса нужных новых возможностей.
Приведем здесь основные из них:
1. Поддержка последних версий платформ виртуализации.
VMware NSX 6.2 поддерживает как VMware vSphere 5.5, так и vSphere 6.0. Новые функции в плане сетевого взаимодействия и безопасности между двумя серверами vCenter поддерживаются только для vSphere 6.0.
2. Возможности Cross vCenter Network Virtualization.
В NSX 6.2 поддерживаются окружения, где логические коммутаторы, распределенные логические маршрутизаторы и распределенные сетевые экраны размещены таким образом, что их действие распространяется на объекты с разными vCenter. Официально эта возможность называется Cross-vCenter Network and Security.
Теперь политики фаервола или логических сетевых компонентов могут быть помечены как Universal, что означает, что настройки реплицируются между модулями NSX Manager и будут сохранены при миграции vMotion виртуальной машины на другой хост ESXi, который находится под управлением другого сервера vCenter.
3. Новые универсальные логические объекты сети.
Universal Logical Switch (ULS) - возможность создания логических коммутаторов, которые объединяют несколько серверов vCenter. Это позволяет создать L2-домен сетевого взаимодействия для приложения в виртуальной машине, которое может "путешествовать" между датацентрами.
Universal Distributed Logical Router (UDLR) - это логический распределенный роутер, осуществляющий маршрутизацию между объектами ULS, описанными выше. Этот маршрутизатор работает также и на базе географического размещения ВМ.
Universal IP sets, MAC sets, security groups, services и service groups - все эти объекты поддерживают распределенные структуры с несколькими vCenter.
4. Поддержка VMware vCenter Server 6 с различными топологиями Platform Services Controller (PSC).
Если раньше NSX поддерживала только встроенные сервисы PSC (Platform Services Controller), то теперь поддерживаются различные распределенные топологии (об этом мы писали вот тут). Теперь полностью поддерживаются такие компоненты, как vCenter SSO, license service, lookup service, VMware Certificate Authority и прочее.
5. Поддержка L2 Bridging для Distributed Logical Router.
L2 bridging теперь может принимать участие в распределенной логической маршрутизации. Сеть VXLAN, к которой присоединен экземпляр бриджинга, используется для взаимосоединения Routing instance и Bridge instance.
6. Новый механизм обнаружения IP-адресов для виртуальных машин.
Ранее IP-адреса виртуальных машин обнаруживались по присутствию в них VMware Tools и добавлялись вручную. Теперь есть 2 новых способа добавления адресов: DHCP snooping и ARP snooping (причем присутствие VMware Tools необязательно).
7. Улучшения средств управления и решения проблем.
Тут появились следующие новые фичи:
Central CLI - единый интерфейс командной строки для обычных и распределенных функций NSX.
Traceflow troubleshooting tool - утилита, которая позволяет понять, возникла проблема в виртуальной или физической сети, за счет слежения за прохождением пакета через виртуальный и физический сетевой стек.
Функции Flow monitoring и IPFix теперь можно включать отдельно (раньше можно было только вместе и это создавало много нагрузочного трафика, особенно в больших окружениях).
Отчет в реальном времени о состоянии управляющих компонентов NSX: состояние связей между NSX Manager и агентом сетевого экрана, NSX Manager и консолью управления, между хостами ESXi и NSX Controller.
8. Улучшения LB Health Monitoring.
Теперь доступен гранулярный мониторинг состояния, который предоставляет информацию о произошедших сбоях, а также отслеживает информацию об изменении состояния компонентов NSX и связей между ними. Помимо этого, также предоставляется информация о возможных причинах сбоев.
9. Поддержка диапазона портов для LB.
Теперь для приложений, которым нужно использовать диапазон портов для LB, есть возможность задать этот диапазон.
10. Прочие улучшения.
Возможность сохранять тэг VLAN при коммуникациях VXLAN.
Просмотр активного узла в HA-паре.
Увеличено максимальное число виртуальных IP-адресов.
Поддержка vRealize Orchestrator Plug-in for NSX 1.0.2.
Возможность включения/отключения uRPF check для отдельного интерфейса.
Улучшения Load balancer health monitoring.
Прочие улучшения, полный список которых приведен вот тут.
Скачать VMware NSX 6.2 можно по этой ссылке. Документация по продукту доступна вот тут.
Кроме того, VMware NSX версии 6.2 поддерживает инфраструктуру виртуальных ПК VMware Horizon View версии 6.0.1 и боее поздних (другие продукты вы тоже можете добавить в VMware Product Interoperability Matrix):
Про поддержку VMware Horizon View есть также небольшое видео:
Недавно компания VMware выпустила очень интересный документ "What’s New in VMware vSphere 6 - Performance", в котором рассказывается о том, какие улучшения были сделаны в новой версии vSphere 6.0, касающиеся различных аспектов производительности платформы (вычислительные ресурсы, хранилища и сети).
Документ выпущен отделом технического маркетинга VMware, и в нем приведены вполне конкретные сведения об увеличении производительности компонентов vSphere.
Например, вот сводная картинка улучшения производительности vCenter (версия 6.0 против 5.5) при тяжелых нагрузках на Microsoft SQL Server 2012 в зависимости от числа объектов, которые находятся под управлением сервиса (размер Inventory). Данные приведены в количестве операций в минуту. Результаты впечатляют:
Улучшения кластеров отказоустойчивых хранилищ VMware Virtual SAN (результаты по конфигурации All-Flash еще не обработаны):
С точки зрения производительности виртуальных сетевых адаптеров VMXNET 3, платформа vSphere 6.0 научилась выжимать из них более 35 гигабит в секунду при работе с физическими адаптерами 40 GbE:
Ну и в целом в документе есть еще много чего интересного - скачивайте.
Как многие из вас знают, в состав платформы виртуализации VMware vSphere 6.0 входит виртуальный модуль VMware vCenter Server Appliance (vCSA) 6.0, который реализует все необходимые сервисы управления виртуальной инфраструктурой в виде уже готовой виртуальной машины на базе Linux.
По умолчанию в данном модуле настроено устаревание пароля в 90 дней, и если в течение этого времени он не был сменен, он устареет и не будет работать. То есть, через три месяца вы увидите вот такую картинку:
Unable to authenticate user. Please try again.
В этом случае вам нужно либо сбросить пароль vCenter Server Appliance и установить новый, либо (если вы помните старый пароль , но он устарел) разлочить аккаунт.
Делается это вот каким образом:
1. Используем какой-нибудь Linux LiveCD (например, KNOPPIX).
Подключаем ISO-шку к виртуальной машине с vCSA и загружаемся с нее в Shell:
Затем повышаем привилегии командой:
# su -
2. Монтируем файловую систему vCSA с помощью команды:
# mount /dev/sda3 /mnt
3. Создаем резервную копию файла с паролем рута и открываем его для редактирования:
# cd /mnt/etc
#
cp shadow shadow.bak
# vi /mnt/etc/shadow
Видим определение пароля root:
4. Если вы помните пароль, а он просто устарел:
В этом случае просто удаляем букву x (выделена желтым) и цифру 1 (также желтая - останется два двоеточия). Нажмите клавишу <i>, чтобы перейти в режим редактирования. После того, как вы внесете нужные изменения, нажмите <esc> и потом напишите ZZ, после чего нажмите ввод, чтобы сохранить изменения.
После перезагрузки vCSA старый пароль root будет работать.
5. Если вы не помните пароль:
Надо заменить его хэш. Сначала смотрим, что стоит в начале строчки. У вас, скорее всего, будет там $6$, что означает, что это хэш, сгенерированный по алгоритму SHA512. От правого доллара конструкции $6$ и до следующего доллара в этой строчке идет так называемая "соль" - это значение вам надо записать на бумажке или сфотать (доллары в него не входят).
Далее генерируем новый пароль, используя записанную соль, следующей командой:
# mkpasswd -m sha-512 <новый пароль> <соль>
Потом получившийся пароль просто вставляем в файл /etc/shadow, который вы только что открывали. Вставляем его от правого доллара, ограничивающего соль, до первого двоеточия. Тут плоховато видно, но суть понятна, куда вставлять этот пароль:
После перезагрузки vCSA вы можете логиниться в него с новым паролем.
Если вы администратор платформы виртуализации VMware vSphere, то, наверное, часто замечали, что в некоторых случаях при операциях с виртуальными машинами и ее дисками происходит "подмораживание" ВМ (или "stun", он же "quiescence"). В этот момент виртуальная машина ничего не может делать - она недоступна для взаимодействия (в консоли и по сети), а также перестает на небольшое время производить операции ввода-вывода. То есть, ее исполнение ставится на паузу на уровне инструкций, а на уровне ввода-вывода совершаются только операции, касающиеся выполняемой задачи (например, закрытие прежнего VMDK-диска и переключение операций чтения-записи на новый диск при операциях со снапшотами).
Cormac Hogan написал на эту тему интересный пост. Stun виртуальной машины нужен, как правило, для того, чтобы сделать ее на время изолированной от окружающего мира для выполнения значимых дисковых операций, например, консолидация снапшотов. Это может занимать несколько секунд (и даже десятков), но часто это происходит на время около секунды и даже меньше.
Когда может возникать stun виртуальной машины? Есть несколько таких ситуаций.
1. Во время операции "suspend" (постановка ВМ на паузу). Тут происходит такое подмораживание, чтобы скинуть память ВМ на диск, после чего перевести ее в приостановленное состояние.
2. В момент создания снапшота. Об этом написано выше - нужно закрыть старый диск и начать писать в новый. На время этой операции логично, что приостанавливается ввод-вывод.
3. Консолидация снапшотов (удаление всех). Здесь тоже нужно "склеить" все VMDK-диски (предварительно закрыв) и начать работать с основным диском ВМ. А вот удаление снапшота в цепочке stun не вызывает, так как не затрагивает VMDK, в который сейчас непосредственно идет запись.
4. Горячая миграция vMotion. Сначала память передается от одной машины к целевой ВМ без подмораживания, но затем происходит такой же stun, как и при операции suspend, с тем только отличием, что маленький остаток памяти (минимальная дельта) передается не на диск, а по сети. После этого происходит операция resume уже на целевом хосте. Пользователь этого переключения, как правило, не замечает, так как время этого переключения очень жестко контролируется и чаще всего не достигает 1 секунды. Если память гостевой ОС будет меняться очень быстро, то vMotion может затянуться именно во время этого переключения (нужно передать последнюю дельту).
5. Горячая миграция хранилищ Storage vMotion. Здесь stun случается аж дважды: сначала vSphere должна поставить Mirror Driver, который будет реплицировать в синхронном режиме операции ввода-вывода на целевое хранилище. При постановке этого драйвера происходит кратковременный stun (нужно также закрыть диски). Но и при переключении работы ВМ на второе хранилище происходит stun, так как нужно удалить mirror driver, а значит снова переоткрыть диски уже на целевом хранилище.
В современных версиях vSphere работа со снапшотами была оптимизирована, поэтому подмораживания виртуальной машины во время этих операций вы почти не заметите.
Давно мы не публиковали сравнений платформ виртуализации VMware vSphere и Microsoft Hyper-V, которые, как известно, лишены смысла (ибо они либо ангажированы, либо сравнивают мягкое с горячим, либо привязываются к конкретному варианту использования). Всем понятно, что VMware - это дорогая и мощная платформа для тех у кого есть деньги, а Microsoft - бюджетная платформа виртуализации серверов в небольших компаниях. И в ближайшие пару лет это вряд ли изменится.
Так вот, оказывается, одно из последних сравнений VMware vSphere 5.1 и Microsoft Hyper-V третьей версии (примерно то, что есть сейчас) мы публиковали аж в 2012 году. Но ведь не так давно компания VMware обновила свое сравнение, включив туда VMware vSphere 6.0, пытаясь, видимо, широко распространить эту презентацию до того, как Microsoft обновит свой Windows Server до платформы vNext (это будет в следующем году).
Ну а мы, без зазрения совести, публикуем здесь это сравнение.
Итак, основные параметры платформ (гипервизора). VMware действительно выигрывает по Enterprise-фичам, но все довольно спорно для SMB:
Обеспечение доступности и защита данных. Здесь VMware, конечно же, впереди. Но нужен ли такой уровень доступности (например, Fault Tolerance) для небольших компаний? Иногда да, но чаще выгоднее сэкономить.
Автоматизация и управление. Ну вот это все точно про крупную организацию:
Ну и традиционный булшит про стоимость владения (его как бы можно посчитать на калькуляторе VMware вот тут). Когда не могут оправдать высокую входную цену продукта - берутся, как правило, заливать про TCO. Типа автоматизация сэкономит вам кучу денег:
Как, помимо прочего, происходит экономия при виртуализации? Типа, говорят, становится меньше дел, и можно сократить "лишних" системных администраторов. На деле же геморроя становится больше, поэтому администратора приходится нанимать.
Как многие из вас знают, в VMware vSphere 6.0 была добавлена функциональности горячей миграции vMotion виртуальной машины между датацентрами под управлением разных серверов vCenter. Виртуальные машины могут теперь перемещаться между виртуальными коммутаторами Standard vSwitch и Distributed Switch (vDS)в любой их комбинации, при этом при уходе с vDS настройки машины на его портах сохраняются и уезжают вместе с ней.
На днях VMware выпустила интересное видео, описывающее данную возможность:
Чтобы машина могла переезжать с одного vCenter на другой в горячем режиме необходимо:
Чтобы оба сервера vCenter были версии 6.0 или более поздней.
Чтобы оба сервера vCenter работали в режиме Enhanced Linked Mode и были в одном домене Single Sign-On, то есть один vCenter (исходный) мог аутентифицироваться на другом (целевом).
Оба сервера vCenter должны быть синхронизированы по времени, чтобы SSO мог корректно производить аутентификацию.
Если вы переносите только ВМ с сервера на сервер (хранилище остается тем же), оба сервера vCenter должны видеть общее хранилище (соответственно, хост-серверы и vCenter должны быть соответствующим образом отзонированы).
Больше подробностей можно узнать из видео выше и KB 2106952.
Практически все администраторы виртуальных инфраструктур обеспокоены проблемой ее производительности в тех или иных условиях. На днях компания VMware обновила свое основное руководство по производительности платформы виртуализации номер один на рынке - Performance Best Practices for VMware vSphere 6.0.
Это не просто очередной whitepaper - это настоящая книга о производительности, на почти 100 страницах которой можно найти не только теоретические советы, но и вполне практичные настройки и конфигурации среды VMware vSphere. К каждому объясняемому параметру заботливо описаны рекомендуемые значения. В общем, Must Read.
Документ состоит из двух частей: в первой части рассказывается о том, как правильно спроектировать кластер vMSC и настроить платформу VMware vSphere соответствующим образом:
Во второй части подробно описаны различные сценарии сбоев и их обработка кластером vMSC в вашей распределенной виртуальной инфраструктуре:
В документе описаны следующие виды сбоев:
Отказ одного хоста в основном датацентре
Изоляция одного хоста в основном датацентре
Разделение пула виртуальных хранилищ
Разделение датацентра на сегменты (сети хостов и сети хранилищ)
Отказ дисковой полки в основном ЦОД
Полный отказ всех хранилищ в основном датацентре
Потеря устройств (полный выход из строя, выведение из эксплуатации) - Permanent Device Loss (PDL)
Понятное дело, что документ обязателен к прочтению, если вы планируете строить распределенную инфраструктуру для ваших виртуальных машин на платформе VMware vSphere 6.0.
В блоге компании VMware появился интересный пост с некоторыми подробностями о работе технологии репликации виртуальных машин vSphere Replication. Приведем здесь основные полезные моменты.
Во-первых, репликация с точки зрения синхронизации данных, бывает двух типов:
Full sync - это когда требуется полная синхронизация виртуальной машины и всех ее дисков в целевое местоположение. Для этого в версии VMware vSphere 5.x использовалось сравнение контрольных сумм дисков на исходном и целевом хранилище. Если они не совпадают, и нужно делать Full sync, исходя из начальных условий - начинается процесс полной репликации ВМ. В первую очередь, основным подвидом этого типа является Initial full sync - первичная синхронизация работающей виртуальной машины, для которой репликация включается впервые.
Кроме того, полная синхронизация включается, когда по какой-либо причине произошла ошибка отслеживания блоков виртуального диска машины при дельта-репликации и передать на целевую ВМ только изменения виртуальных дисков становится невозможным.
Delta sync - после того, как полная синхронизация закончена, начинается процесс передачи целевой ВМ только различий с момента полной репликации. Тут используется технология changed block tracking, чтобы понять, какие блоки надо отреплицировать с последнего Full sync. Периодичность дельта-репликации зависит от установленной политики Recovery Point Objective (RPO).
Чтобы политика RPO соблюдалась нужно, чтобы дельта-синхронизация полностью проходила за половину времени, установленного в RPO, иначе будут нарушения политики, сообщения о которых вы увидите в vSphere Client. Почему половину? Подробно мы писали об этом вот тут (почитайте, очень интересно). Также еще и в документации VMware есть информация о расписании репликации.
Если вы настроите репликацию для виртуальной машины, то автоматически работать она будет для включенной ВМ, а если она выключена, то сама работать не будет, о чем будет выдано соответствующее предупреждение:
Вот так запускается репликация для выключенной ВМ:
Во время offline-репликации виртуальную машину нельзя включить, а ее диски будут залочены. Кроме того, вы не сможете отменить эту операцию. Поэтому при нажатии Sync Now будет выведено вот такое предупреждение:
Обычно offline-репликация используется для создания гарантированной копии ВМ на другой площадке (например, при переезде датацентра или частичном восстановлении инфраструктуры на другом оборудовании). Ну или если у вас была настроена online-репликация, а вы выключили ВМ, то в конце нужно сделать еще ручной Sync Now.
Также в VMware vSphere 6.0 было сделано существенное улучшение в производительности процесса репликации. Если раньше идентичность копий основного диска и реплики сверялась только на базе контрольных сумм (все данные диска надо прочитать - а это затратно по вводу-выводу и CPU), то теперь иногда используются данные о конфигурации виртуального диска на базе регионов. Например, если на исходном диске есть регионы, которые не были аллоцированы на целевом диске, то репликация это отслеживает и передает данные в эти регионы на целевое хранилище. Это работает значительно быстрее вычисления контрольных сумм.
Но такая оптимизация работает не для всех типов виртуальных дисков, а только для Lazy zeroed thick disks, thin disks и vSAN sparse disks и только на томах VMFS. Тома NFS, тома VVols, а также диски типа Eager zeroed thick не предоставляют информации об аллокации регионов, поэтому для них оптимизация работать не будет. Более подробно об этом написано тут.
Не так давно мы писали о том, что компания VMware выпустила бета-версию своего основного руководства по обеспечению информационной безопасности виртуальной инфраструктуры vSphere 6.0 Hardening Guide. На днях же вышла финальная версия этого документа. Надо отметить, что документ весьма сильно поменялся по структуре и содержанию:
Согласно записи в блоге VMware, в данной версии руководства были сделаны следующие позитивные изменения:
Сделан упор на автоматизацию воплощения рекомендаций через API, чтобы доставить меньше хлопот по ручному конфигурированию настроек. Приводятся конкретные команды PowerCLI и vCLI для исследования конфигураций и задания необходимых параметров.
В качестве рекомендуемого значения добавлен параметр "site-specific", что означает, что конкретная имплементация данной настройки зависит от особенностей инфраструктуры пользователя.
Появилась колонка с разносторонним обсуждением проблемы потенциальной уязвимости (с учетом предыдущего пункта).
Дается больше информации о потенциальных рисках - на что влияет данная настройка в итоге.
Кстати, вот полный список руководящих документов по обеспечению безопасности других продуктов компании VMware и прошлых версий VMware vSphere:
Ну и надо обязательно добавить, что VMware Configuration Manager теперь полностью поддерживает конфигурации из руководства vSphere 6 Hardening Guide. Более подробно об этом написано в блоге VMware Security.
В середине весны компания Symantec выпустила обновление своего продукта для резервного копирования данных физических и виртуальных машин Symantec Backup Exec 15. Этот продукт стал одним из первых, кто поддержал все новые фичи VMware vSphere 6, такие как Virtual Volumes (VVols) и Virtual SAN 6.0. Теперь это действительно удобное комплексное решение как для резервного копирования ВМ в гетерогенной виртуальной среде (VMware vSphere и Microsoft Hyper-V), так и для бэкапа данных физической инфраструктуры с корпоративными приложениями, такими как Microsoft SQL Server или Sharepoint.
В новой версии VMware vSphere 6 для хостов ESXi было сделано следующее нововведение в плане безопасности - теперь после 10 неудачных попыток входа наступает блокировка учетной записи (account lockout), которая длится 2 минуты.
Этот эффект наблюдается теперь при логине через SSH, а также при доступе через vSphere Client (ну и в целом через vSphere Web Services SDK). При локальном доступе через DCUI (напрямую из консоли) такого нет.
Сделано это понятно зачем - чтобы никто не перебирал пароли рута брутфорсом.
Отрегулировать настройки блокировки можно в следующих параметрах Advanced Options хоста ESXi:
Security.AccountLockFailures - максимальное число попыток входа, после которого аккаунт блокируется. Если поставить 0, то функция локаута будет отключена.
Security.AccountUnlockTime - число секунд, на которое блокируется аккаунт.
Если вкратце, то компоненты vCenter предлагается защищать с помощью следующих решений:
1. Кластер высокой доступности VMware HA и сервис слежения за vCenter - Watchdog.
Сервис HA автоматически перезапускает виртуальную машину с vCenter отказавшего сервера на другом хосте кластера, а сервис Watchdog (он есть как на обычном vCenter, так и на vCenter Server Appliance) следит за тем, чтобы основная служба vCenter работала и отвечала, и запускает/перезапускает ее в случае сбоя.
2. Защита средствами VMware Fault Tolerance.
Теперь технология VMware FT в VMware vSphere 6.0 позволяет защищать ВМ с несколькими vCPU, поэтому данный способ теперь подходит для обеспечения непрерывной доступности сервисов vCenter и мгновенного восстановления в случае сбоя оборудования основного хоста ESXi.
Компания VMware предоставляет специализированный API, который могут использовать партнеры для создания решений, защищающих приложения в гостевой ОС, в частности, сервис vCenter. Одно из таких приложений - Symantec ApplicationHA. Оно полностью поддерживает vCenter, имеет специализированного агента и перезапускает нужные службы в случае сбоя или зависания сервиса.
4. Средства кластеризации на уровне гостевой ОС (с кворумным диском).
Это один из древнейших подходов к защите сервисов vCenter. О нем мы писали еще вот тут.
Для организации данного типа защиты потребуется основная и резервная ВМ, которые лучше разместить на разных хостах vCenter. С помощью кластера Windows Server Failover Clustering (WSFC) организуется кворумный диск, общий для виртуальных машин, на котором размещены данные vCenter. В случае сбоя происходит переключение на резервную ВМ, которая продолжает работу с общим диском. Этот метод полностью поддерживается с vCenter 6.0:
Кстати, в документе есть пошаговое руководство по настройке кластера WSFC для кластеризации vCenter 6.0 (не забудьте потом, где его искать).
Ну и в заключение, сводная таблица по функциям и преимуществам приведенных методов:
Далее идет описание средств высокой доступности в Enterprise-инфраструктуре с несколькими серверами vCenter, где компоненты PSC (Platform Services Controller) и vCenter разнесены по разным серверам. Схема с использованием балансировщика:
Обратите внимание, что для PSC отказоустойчивость уже встроена - они реплицируют данные между собой.
Та же схема, но с кластеризованными серверами vCenter средствами технологии WSFC:
Использование географически распределенных датацентров и сервисов vCenter в них в едином домене доступа SSO (Single Sign-On) за счет технологии Enhanced Linked Mode (каждый сайт независим):
То же самое, но со схемой отказоустойчивости на уровне каждой из площадок:
Ну и напоследок 2 дополнительных совета:
1. Используйте Network Teaming для адаптеров vCenter (физических или виртуальных) в режиме отказоустойчивости, подключенные к дублирующим друг друга сетям.
2. Используйте Anti-affinity rules кластера HA/DRS, чтобы основная и резервная машина с vCenter не оказались на одном хосте VMware ESXi.
Да, и не забывайте о резервном копировании и репликации виртуальной машины с vCenter. Сделать это можно либо средствами Veeam Backup and Replication 8, либо с помощью VMware vSphere Replication/VMware vSphere Data Protection.
Компания VMware в своем блоге затронула интересную тему - обновление микрокода для процессоров платформ Intel и AMD в гипервизоре VMware ESXi, входящем в состав vSphere. Суть проблемы тут такова - современные процессоры предоставляют возможность обновления своего микрокода при загрузке, что позволяет исправлять сделанные вендором ошибки или устранять проблемные места. Как правило, обновления микрокода идут вместе с апдейтом BIOS, за которые отвечает вендор процессоров (Intel или AMD), а также вендор платформы (HP, Dell и другие).
Между тем, не все производители платформ делают обновления BIOS своевременно, поэтому чтобы получить апдейт микрокода приходится весьма долго ждать, что может быть критичным если ошибка в текущей версии микрокода весьма серьезная. ESXi имеет свой механизм microcode loader, который позволяет накатить обновления микрокода при загрузке в том случае, если вы получили эти обновления от вендора и знаете, что делаете.
Надо сказать, что в VMware vSphere 6.0 обновления микрокода накатываются только при загрузке и только на очень ранней стадии, так как более поздняя загрузка может поменять данные, уже инициализированные загрузившимся VMkernel.
Сама VMware использует тоже не самые последние обновления микрокода процессоров, так как в целях максимальной безопасности накатываются только самые критичные апдейты, а вендоры платформ просят время на тестирование обновлений.
Есть два способа обновить микрокод процессоров в ESXi - через установку VIB-пакета и через обновление файлов-пакетов микрокода на хранилище ESXi. Если вы заглянете в папку /bootbank, то увидите там такие файлы:
uc_amd.b00
uc_intel.b00
Эти файлы и содержат обновления микрокода и идут в VIB-пакете cpu-microcode гипервизора ESXi. Ниже опишем процедуру обновления микрокода для ESXi с помощью обоих методов. Предпочтительный метод - это делать апдейт через VIB-пакет, так как это наиболее безопасно. Также вам потребуется Lunix-машина для манипуляций с микрокодом. Все описанное ниже вы делаете только на свой страх и риск.
После распаковки вы получите файл microcode.dat. Это файл в ASCII-формате, его надо будет преобразовать в бинарный. У AMD в репозитории есть сразу бинарные файлы (3 штуки, все нужные).
2. Делаем бинарный пакет микрокода.
Создаем следующий python-скрипт и называем его intelBlob.py:
#! /usr/bin/python
# Make a raw binary blob from Intel microcode format.
# Requires Python 2.6 or later (including Python 3)
# Usage: intelBlob.py < microcode.dat microcode.bin
import sys
outf = open(sys.argv[1], "wb")
for line in sys.stdin:
if line[0] == '/':
continue
hvals = line.split(',')
for hval in hvals:
if hval == '\n' or hval == '\r\n':
continue
val = int(hval, 16)
for shift in (0, 8, 16, 24):
outf.write(bytearray([(val >> shift) & 0xff]))
Тут все просто. Выполним одну из следующих команд для полученных файлов:
cp uc_intel.gz /bootbank/uc_intel.b00
cp uc_amd.gz /bootbank/uc_amd.b00
Далее можно переходить к шагу 5.
4. Метод создания VIB-пакета и его установки.
Тут нужно использовать утилиту VIB Author, которую можно поставить на Linux-машину (на данный момент утилита идет в RPM-формате, оптимизирована под SuSE Enterprise Linux 11 SP2, который и предлагается использовать). Скачайте файл cpu-microcode.xml и самостоятельно внесите в него изменения касающиеся версии микрокода.
Затем делаем VIB-пакет с помощью следующей команды:
Затем проверьте наличие файлов uc_*.b00, которые вы сделали на шаге 2, в директории /altbootbank.
5. Тестирование.
После перезагрузки хоста ESXi посмотрите в лог /var/log/vmkernel.log на наличие сообщений MicrocodeUpdate. Также можно посмотреть через vish в файлы /hardware/cpu/cpuList/*, в которых где-то в конце будут следующие строчки:
Number of microcode updates:1
Original Revision:0x00000011
Current Revision:0x00000017
Это и означает, что микрокод процессоров у вас обновлен. ESXi обновляет микрокод всех процессоров последовательно. Вы можете проверит это, посмотрев параметр Current Revision.
Также вы можете запретить на хосте любые обновления микрокода, установив опцию microcodeUpdate=FALSE в разделе VMkernel boot. Также по умолчанию запрещено обновление микрокода на более ранние версии (даунгрейд) и на экспериментальные версии. Это можно отключить, используя опцию microcodeUpdateForce=TRUE (однако микрокод большинства процессоров может быть обновлен только при наличии цифровой подписи вендора). Кроме того, чтобы поставить экспериментальный апдейт микрокода, нужно включить опции "debug mode" или "debug interface" в BIOS сервера, после чего полностью перезагрузить его.
Как вы все знаете, недавно вышла платформа виртуализации VMware vSphere 6.0, и мы много писали о ее новых возможностях. На одном из блогов появились полезные таблички, в которых просто и понятно описаны численные и качественные улучшения VMware vSphere 6.0 по сравнению с прошлыми версиями - 5.1 и 5.5. Приведем их тут.
Улучшения гипервизора VMware ESXi:
Улучшения на уровне виртуальных машин:
Улучшения на уровне средства управления VMware vCenter:
Не так давно мы писали про архитектуру и возможности технологии VVols в VMware vSphere 6, которая позволяет использовать хранилища виртуальных машин напрямую в виде томов на дисковом массиве за счет использования аппаратных интеграций VASA (vSphere APIs for Storage Awareness).
На днях компания VMware выпустила на эту тему преинтересный документ "vSphere Virtual Volumes Getting Started Guide", который вкратце описывает саму технологию, а также приводит пошаговое руководство по использованию vSphere Web Client для быстрого старта с VVols:
Основные темы документа:
Компоненты vSphere Virtual Volumes
Требования для развертывания VVols
Настройка VVols на практике
Совместимость VVols с другими продуктами и технологиями VMware
Команды vSphere Virtual Volumes CLI
Интересно также рассматривается архитектура взаимодействия между компонентами VVols:
Документ интересный и полезный, так как составлен в виде пошагового руководства по настройке политик хранения, маппинга хранилищ на эти политики и развертывания ВМ на томах VVols.
Таги: VMware, VVols, Whitepaper, vSphere, Web Client
Компания Veeam, как всегда первой проявила инициативу и оперативность в этом вопросе - вышел Veeam Availability Suite v8 Update 2, все компоненты которого полностью поддерживают vSphere 6. Полностью - это значит, что Veeam ONE v8 Update 2 - единое решение для мониторинга и отчетности в виртуальной среде, а также Veeam Backup and Replication v8 Update 2 - продукт номер 1 для резервного копирования виртуальных машин, полностью работают с шестой версией платформы виртуализации от VMware и не имеют там никаких ограничений.
Кроме этого, в Veeam Availability Suite v8 Update 2 появились следующие новые возможности, недоступные в продуктах других вендоров:
Поддержка VMware Virtual Volumes (VVols) и VMware Virtual SAN 2.0.
Механизм Storage Policy-Based Management (SPBM) для резервного копирования и восстановления (управление на базе политик).
Возможность резервного копирования и репликации машин, защищенных технологией Fault Tolerance (FT). Это очень круто!
Интеграция с тэгами vSphere 6.
Поддержка Cross-vCenter vMotion.
Поддержка функций Quick Migration на тома VVols (переезд машин с классических VMFS-хранилищ).
Режим транспорта данных Hot-Add для виртуальных SATA-дисков.
То есть теперь при восстановлении ВМ можно выбирать хранилище, подпадающее под определенные политики (по умолчанию будет использована исходная политика):
Также появилась поддержка продукта Veeam Endpoint Backup FREE. Теперь в консоли Veeam Backup & Replication мы видим бэкапы с рабочих станций и серверов, сделанные средствами Endpoint Backup.
Вот тут, например, мы задаем репозиторию пермиссии на сохранение в него бэкапов Veeam Endpoint Backup FREE:
Veeam ONE v8 Update 2 тоже получил несколько новых возможностей и теперь поддерживает мониторинг всех компонентов vSphere 6, включая такие как, например, тома VVols.
Некоторое время назад мы писали про обработку гипервизором VMware vSphere таких состояний хранилища ВМ, как APD (All Paths Down) и PDL (Permanent Device Loss). Вкратце: APD - это когда хост-сервер ESXi не может получить доступ к устройству ни по одному из путей, а также устройство не дает кодов ответа на SCSI-команды, а PDL - это когда хост-серверу ESXi удается понять, что устройство не только недоступно по всем имеющимся путям, но и удалено совсем, либо сломалось.
Так вот, в новой версии VMware vSphere 6.0 появился механизм VM Component Protection (VMCP), который позволяет обрабатывать эти ситуации со стороны кластера высокой доступности VMware HA в том случае, если в нем остались другие хосты, имеющие доступ к виртуальной машине, оставшейся без "хост-хозяина".
Для того чтобы это начало работать, нужно на уровне кластера включить настройку "Protect against Storage Connectivity Loss":
Далее посмотрим на настройки механизма Virtual Machine Monitoring, куда входят и настройки VM Component Protection (VMCP):
С ситуацией PDL все понятно - хост больше не имеет доступа к виртуальной машине, и массив знает об этом, то есть вернул серверу ESXi соответствующий статус - в этом случае разумно выключить процесс машины на данном хосте и запустить ВМ на других серверах. Тут выполняется действие, указанное в поле Response for a Datastore with Permanent Device Loss (PDL).
Со статусом же APD все происходит несколько иначе. Поскольку в этом состоянии мы не знаем пропал ли доступ к хранилищу ВМ ненадолго или же навсегда, происходит все следующим образом:
возникает пауза до 140 секунд, во время которой хост пытается восстановить соединение с хранилищем
если связь не восстановлена, хост помечает датастор как недоступный по причине APD Timout
далее VMware HA включает счетчик времени, который длится ровно столько, сколько указано в поле Delay for VM failover for APD (по умолчанию - 3 минуты)
по истечении этого времени начинается выполнение действия Response for a Datastore with All Paths Down (APD), а само хранилище помечается как утраченное (NO_Connect)
У такого механизма работы есть следующие особенности:
VMCP не поддерживает датасторы Virtual SAN - они будут просто игнорироваться.
VMCP не поддерживает Fault Tolerance. Машины, защищенные этой технологией, будут получать перекрывающую настройку не использовать VMCP.
Компания VMware довольно оперативно выставила на всеобщее обсуждение бета-версию своего основного руководства по обеспечению информационной безопасности виртуальной инфраструктуры vSphere 6.0 Hardening Guide.
В этой Excel-табличке на данный момент общим списком собраны основные рекомендации (подчеркнем, что список неполный, и в релизной версии рекомендаций будет больше). Часть рекомендаций была удалена из руководства или перемещена в документацию - список этих пунктов приведен вот тут.
Основное, что ушло из руководства - это операционные рекомендации, то есть что следует делать правильно во время эксплуатации VMware vSphere. Это переместилось в соответствующие разделы документации по платформе. В итоге, осталась сухая выжимка из необходимых настроек безопасности, которые нужно правильно применять в своей инфраструктуре.
Гайдлайны сгруппированы в профили риска (Risk Profiles) - их всего три штуки (1, 2, 3), и они определяют степень критичности их применения. Уровень 1 - только для высокозащищенных систем, 2 - для окружений с чувствительными данными (например, персональными), 3 - для обычных производственных систем.
Также прибавились префиксы компонентов для рекомендаций:
Было: enable-ad-auth
Стало: ESXi.enable-ad-auth
Кстати, интересное видео о том, как нужно использовать Hardening Guide:
Компания VMware с радостью примет пожелания и замечания к руководству, которые можно оставить вот тут. Релиз финальной версии VMware vSphere 6.0 Hardening Guide ожидается во втором квартале 2015 года.
Не так давно мы писали про технологию Virtual Volumes (VVols), которая полноценно была запущена в новой версии платформы виртуализации VMware vSphere 6. VVols - это низкоуровневое хранилище для виртуальных машин, с которым позволены операции на уровне массива по аналогии с теми, которые доступны для традиционных LUN - например, снапшоты дискового уровня, репликация и прочее.
VVols - это один из типов хранилищ (Datastore) в vSphere:
Тома vVOLs создаются на дисковом массиве при обращении платформы к новой виртуальной машине (создание, клонирование или снапшот). Для каждой виртуальной машины и ее файлов, которые вы сейчас видите в папке с ВМ, создается отдельный vVOL.
Многие администраторы задаются вопросом: а почему VVols - это крутая штука, нужны ли они вообще? VMware в своем блоге отвечает на этот вопрос. Попробуем изложить их позицию здесь вкратце.
Ну, во-первых, VVols дают возможность создавать аппаратные снапшоты, клоны и снапклоны на уровне одной виртуальной машины, а не целых LUN, но это неконцептуально. Вопрос следует понимать глубже.
Все идет из концепции SDDC (Software Defined Datacenter), которая подразумевает абстракцию всех уровней аппаратных компонентов (вычислительные ресурсы, сети, хранилища) на программный уровень таким образом, чтобы администратор виртуальных ресурсов не ломал себе голову насчет физического устройства датацентра при развертывании новых систем. Иными словами, при создании виртуальной машины администратор должен определить требования к виртуальной машине в виде политики (например система Tier 1), а программно-определяемый датацентр сам решит где и как эту машину разместить (хост+хранилище) и подключить ее к сети (тут вспомним про продукт VMware NSX).
С точки зрения хранилищ (SDS - software defined storage) эта концепция реализуется через подход Storage Policy Based Management (SPBM), предполагающий развертывание новых систем на хранилищах, которые описаны политиками. Этого мы уже касались в статье "VMware vSphere Storage DRS и Profile Driven Storage - что это такое и как работает".
Если раньше дисковый массив определял возможности хранилища, на котором размещалась ВМ (через LUN для Datastore), и машина довольствовалась тем, что есть, то теперь подход изменился: с Virtual Volumes, к которым привязаны политики виртуальных машин, сама машина "рассказывает" о своих требованиях дисковому массиву, который уже ищет, где он может ее "поселить". Этот подход является более правильным с точки зрения автоматизации и человеческого фактора (ниже расскажем почему).
Представим, что у нас есть три фактора, которые определяют качество хранилища:
Тип избыточности и размещения данных (например, RAID - Stripe/Mirror)
Наличие дедупликации (да/нет)
Тип носителя (Flash/SAS/SATA)
Это нам даст 12 возможных комбинаций типов LUN, которые мы можем создать на дисковом массиве:
Соответственно, чтобы учесть все такие комбинации требований при создании виртуальных хранилищ (Datastores), мы должны были бы создать 12 LUN. Но на этом проблемы только начинаются, так как администратор всегда стремится выбрать лучшее с его точки зрения доступное хранилище, что может привести к тому, что LUN1 у нас будет заполнен под завязку системами разной критичности, а новые критичные системы придется размещать на LUN более низкого качества.
На помощь тут приходят политики хранилищ (VM Storage Policies). Например, мы создаем политики Platinum, Silver и Gold, для которых определяем необходимые поддерживаемые хранилищами функции, которые обоснованы, например, критичностью систем:
Если говорить о примере выше, то Platinum - это, например, хранилище с характеристиками LUN типов 1 и 3.
Интерфейс vSphere Web Client нам сразу показывает совместимые и несовместимые с этими политиками хранилища:
Так вот при развертывании новой ВМ администратору должно быть более-менее неважно, на каком именно массиве или LUN будет расположена машина, он должен будет просто выбрать политику, которая отражает его требования к хранилищу. Удобно же!
При создании политики администратор просто выбирает провайдера сервисов хранения (в данном случае массив NetApp с поддержкой VVols) и определяет необходимые поддерживаемые фичи для набора правил в политике:
После этого при развертывании новой виртуальной машины администратор просто выбирает нужную политику, зная обеспечиваемый ей уровень обслуживания, и хранилищем запускается процесс поиска места для новой ВМ (а точнее, ее объектов) в соответствии с определенными в политике требованиями. Если эти требования возможно обеспечить, то создаются необходимые тома VVOls (как бы отдельные LUN для объектов машины). Таким образом, с помощью политик машины автоматически "вселяются" в пространство хранения дисковых массивов в соответствии с требованиями, не позволяя субъективному человеку дисбалансировать распределение машин по хранилищам различных ярусов. Вот тут и устраняется человеческий фактор, и проявляется сервисно-ориентированный подход: не машину "селят" куда скажет дядя-админ, а система выбирает хранилище для ВМ, которое соответсвует ее требованиям.
Вскоре после выхода платформы виртуализации VMware vSphere 6.0 компания VMware выпустила апрельский патч VMware ESXi 6.0 (Build 2615704). Обновление ESXi600-201504001 описано в KB 2111975. В данном билде есть только исправления багов, его статус - Critical.
Какие ошибки были исправлены:
Выпадение в "розовый экран смерти" при промотке логов хоста через прямое подключение к консоли сервера - DCUI (по комбинации клавиш ALT+F12).
Stateless-хосты VMware ESXi (бездисковые, загруженные в память) могут упасть при применении профиля из VMware Host Profiles (с ошибкой A specified parameter was not correct: dvsName).
Производительность виртуальной машины с ОС Windows, для которой включена технология Fault Tolerance, может неожиданно сильно упасть.
Баг с непредоставлением сервером vCenter лицензии stateless-хосту.
Когда у вас много виртуальных машин с небольшой памятью (< 128 МБ), в процессе NUMA remapping может выскочить "розовый экран смерти".
Как мы видим, баги в ESXi 6.0 еще есть, и пока некуда торопиться с обновлением с версий 5.x.
Скачать апрельский патч VMware ESXi 6.0 (Build 2615704) можно с VMware Patch Portal, введя номер билда в поиск.
Незадолго до выпуска платформы виртуализации VMware vSphere 6 компания VMware решила обновить пути сертификации технических специалистов по продуктам линейки, привязанных к шестой версии базового продукта. Итак, теперь у нас есть Certification Roadmap for 2015, которая графически представлена следующим образом...
Какое-то время назад мы писали о том, что на сайте проекта VMware Labs доступен пакет VMware Tools для виртуальных серверов VMware ESXi, работающих как виртуальные машины. В версии VMware vSphere 6 этот пакет по умолчанию уже вшит в ESXi 6.0, и ничего ставить дополнительно не нужно:
Это можно также просто проверить с помощью консольной команды:
Как вы знаете, в обновленной версии платформы виртуализации VMware vSphere 6.0 появились не только новые возможности, но и были сделаны существенные улучшения в плане производительности (например, вот).
В компании VMware провели тест, использовав несколько виртуальных машин с базами данных SQL Server, где была OLTP-модель нагрузки (то есть большой поток небольших транзакций). Для стресс-теста БД использовалась утилита DVD Store 2.1. Архитектура тестовой конфигурации:
Сначала на хосте с 4 процессорами (10 ядер в каждом) запустили 8 виртуальных машин с 8 vCPU на борту у каждой, потом же на хосте 4 процессорами и 15 ядер в каждом запустили 8 ВМ с 16 vCPU. По количеству операций в минуту (Operations per minute, OPM) вторая конфигурация показала почти в два раза лучший результат:
Это не совсем "сравнение яблок с яблоками", но если понимать, что хосты по производительности отличаются не в два раза - то результат показателен.
Интересен также эксперимент с режимом Affinity у процессоров для "большой" виртуальной машины. В первом случае машину с 60 vCPU привязали к двум физическим процессорам хоста (15 ядер на процессор, итого 30 ядер, но использовалось 60 логических CPU - так как в каждом физическом ядре два логических).
Во втором же случае дали машине те же 60 vCPU и все оставили по дефолту (то есть позволили планировщику ESXi шедулить исполнение на всех физических ядрах сервера):
Результат, как мы видим, показателен - физические ядра лучше логических. Используйте дефолтные настройки, предоставьте планировщику ESXi самому решать, как исполнять виртуальные машины.
Как мы видим, за 7 лет размер вырос не катастрофически - всего в три раза. Посмотрите на продукты других вендоров и поймете, что это не так уж и много.
На диаграмме:
Как автор вычислял размер гипервизора? Он сравнил размер следующих пакетов, содержащих в себе компоненты ESXi:
Пакет "image" в ESXi 3.5
Пакет "firmware" в ESXi 4.x
VIB-пакет "esx-base" в ESXi 5.x и 6.x
Табличка размеров гипервизора для всех версий (не только мажорных):
ESXi
Size
4.0
57,80 MB
4.0 U1
58,82 MB
4.0 U2
59,11 MB
4.0 U3
59,72 MB
4.0 U4
59,97 MB
4.0 LATEST
59,99 MB
4.1
85,45 MB
4.1 U1
85,89 MB
4.1 U2
85,25 MB
4.1 U3
85,27 MB
4.1 LATEST
85,19 MB
5.0
133,64 MB
5.0 U1
132,32 MB
5.0 U2
132,27 MB
5.0 U3
132,56 MB
5.0 LATEST
132,75 MB
5.1
124,60 MB
5.1 U1
124,88 MB
5.1 U2
125,67 MB
5.1 U3
125,85 MB
5.1 LATEST
125,85 MB
5.5
151,52 MB
5.5 U1
152,24 MB
5.5 U2
151,71 MB
5.5 LATEST
151,98 MB
6.0
154,90 MB
Но почему ISO-образ ESXi 6.0 занимает 344 МБ, а не 155 МБ? Потому что есть еще пакет VMware Tools для различных гостевых ОС (а их поддерживается очень много) плюс драйверы устройств серверов.

 RSS
RSS